Higher-order Statistics
Terriberry extends Chan's formulae to calculating the third and fourth central moments, needed for example when estimating skewness and kurtosis:

Here the are again the sums of powers of differences from the mean, giving
- skewness:
- kurtosis:
For the incremental case (i.e., ), this simplifies to:
By preserving the value, only one division operation is needed and the higher-order statistics can thus be calculated for little incremental cost.
An example of the online algorithm for kurtosis implemented as described is:
def online_kurtosis(data): n = 0 mean = 0 M2 = 0 M3 = 0 M4 = 0 for x in data: n1 = n n = n + 1 delta = x - mean delta_n = delta / n delta_n2 = delta_n * delta_n term1 = delta * delta_n * n1 mean = mean + delta_n M4 = M4 + term1 * delta_n2 * (n*n - 3*n + 3) + 6 * delta_n2 * M2 - 4 * delta_n * M3 M3 = M3 + term1 * delta_n * (n - 2) - 3 * delta_n * M2 M2 = M2 + term1 kurtosis = (n*M4) / (M2*M2) - 3 return kurtosisPébay further extends these results to arbitrary-order central moments, for the incremental and the pairwise cases. One can also find there similar formulas for covariance.
Choi and Sweetman offer two alternate methods to compute the skewness and kurtosis, each of which can save substantial computer memory requirements and CPU time in certain applications. The first approach is to compute the statistical moments by separating the data into bins and then computing the moments from the geometry of the resulting histogram, which effectively becomes a one-pass algorithm for higher moments. One benefit is that the statistical moment calculations can be carried out to arbitrary accuracy such that the computations can be tuned to the precision of, e.g., the data storage format or the original measurement hardware. A relative histogram of a random variable can be constructed in the conventional way: the range of potential values is divided into bins and the number of occurrences within each bin are counted and plotted such that the area of each rectangle equals the portion of the sample values within that bin:
where and represent the frequency and the relative frequency at bin and  is the total area of the histogram. After this normalization, the raw moments and central moments of can be calculated from the relative histogram:
is the total area of the histogram. After this normalization, the raw moments and central moments of can be calculated from the relative histogram:


where the superscript indicates the moments are calculated from the histogram. For constant bin width  these two expressions can be simplified using :
these two expressions can be simplified using :


The second approach from Choi and Sweetman is an analytical methodology to combine statistical moments from individual segments of a time-history such that the resulting overall moments are those of the complete time-history. This methodology could be used for parallel computation of statistical moments with subsequent combination of those moments, or for combination of statistical moments computed at sequential times.
If sets of statistical moments are known: 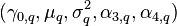 for, then each can be expressed in terms of the equivalent raw moments:
for, then each can be expressed in terms of the equivalent raw moments:

where is generally taken to be the duration of the time-history, or the number of points if is constant.
The benefit of expressing the statistical moments in terms of is that the sets can be combined by addition, and there is no upper limit on the value of .

where the subscript represents the concatenated time-history or combined . These combined values of can then be inversely transformed into raw moments representing the complete concatenated time-history

Known relationships between the raw moments and the central moments are then used to compute the central moments of the concatenated time-history. Finally, the statistical moments of the concatenated history are computed from the central moments:
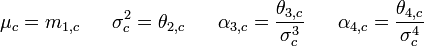
Read more about this topic: Algorithms For Calculating Variance
Famous quotes containing the word statistics:
“July 4. Statistics show that we lose more fools on this day than in all the other days of the year put together. This proves, by the number left in stock, that one Fourth of July per year is now inadequate, the country has grown so.”
—Mark Twain [Samuel Langhorne Clemens] (1835–1910)